O que é um sidecar?
Hospedar um LLM como sidecar para seu aplicativo sem servidor?
📦 O que é um sidecar?
Na arquitetura de software, um sidecar é um componente que roda “ao lado” do seu aplicativo principal. Ele é tipo aquele ajudante silencioso que não aparece no palco, mas está ali nos bastidores fazendo tudo funcionar — sem ser o protagonista.
Exemplo clássico: você tem um app que processa pedidos. Em vez de botar um LLM dentro do código do app, você coloca o modelo como um serviço separado (o sidecar), e o app conversa com ele por API.
☁️ E o que é sem servidor (serverless)?
Serverless não significa “sem servidor”, e sim que você não precisa gerenciar o servidor. Quem cuida disso é o provedor (como AWS Lambda, Google Cloud Functions etc.). Você escreve suas funções e elas rodam “na nuvem”, escalando conforme a demanda.
🤖 Como fica a combinação?
Hospedar um LLM como sidecar para um app serverless significa:
- Seu app principal roda como funções serverless (tipo AWS Lambda).
- O LLM roda em outro lugar (em outro contêiner, serviço ou até numa máquina dedicada).
- Eles se comunicam por API. A função chama o LLM só quando precisa.
🛠️ Vantagens:
- Separação de responsabilidades: o LLM cuida só da IA; o app cuida da lógica.
- Escalabilidade: cada parte escala de forma independente.
- Atualização fácil: dá pra trocar o modelo sem mexer no app.
- Serverless + sidecar = menos dor de cabeça com infraestrutura.
⚠️ Desafios:
- Latência: pode haver um delay extra na comunicação.
- Custo: LLMs são famintos por recursos. Rolar em GPU? A conta sobe.
- Gerenciamento do LLM: você precisa cuidar da hospedagem do modelo em algum lugar (Kubernetes, VM, HuggingFace Inference Endpoints, etc).
🧠 Exemplo prático:
Imagina que você tem um site serverless de turismo (tipo o teu Vaitour) e quer usar IA pra gerar roteiros personalizados. Você pode:
- Roda o front e as funções como serverless (ex: Firebase, AWS).
- Roda um LLM como sidecar (em um serviço à parte).
- Quando o cliente pedir um roteiro, sua função chama o LLM por API, recebe o texto gerado e entrega.
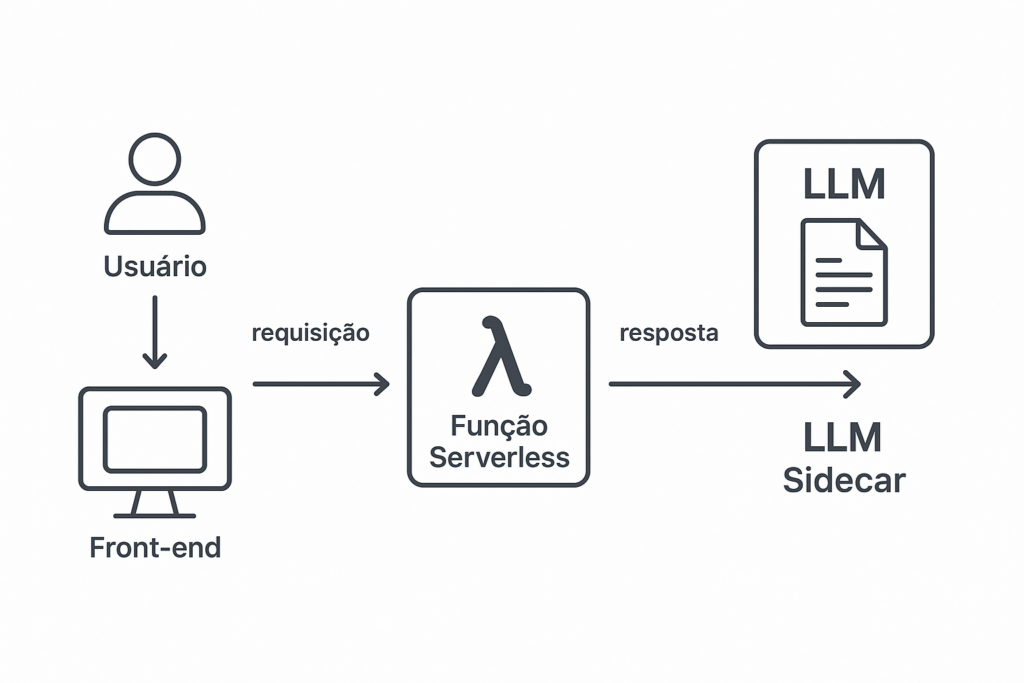
🧭 Diagrama da Arquitetura
csharpCopiarEditar[Usuário]
⬇️
[Front-end (ex: site do Vaitour)]
⬇️ requisita
[Função Serverless (ex: AWS Lambda)]
⬇️ envia requisição
[LLM Sidecar (API do modelo)]
⬇️ resposta
[Função Serverless]
⬇️ envia pra
[Front-end]
const axios = require('axios');
exports.handler = async (event) => {
const { destino, perfil } = JSON.parse(event.body);
try {
// Chamada para o LLM rodando como sidecar
const response = await axios.post('http://llm-sidecar.local/api/generate', {
prompt: `Crie um roteiro de viagem para ${destino} para um viajante com perfil ${perfil}.`,
});
return {
statusCode: 200,
body: JSON.stringify({
roteiro: response.data.roteiro,
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: 'Erro ao gerar roteiro.' }),
};
}
};
🧩 Código exemplo — Função Serverless chamando o LLM
Vamos supor que o sidecar LLM está exposto em http://llm-sidecar.local/api/generate.
🔧 Exemplo em JavaScript (Node.js para AWS Lambda)
const axios = require('axios');
exports.handler = async (event) => {
const { destino, perfil } = JSON.parse(event.body);
try {
// Chamada para o LLM rodando como sidecar
const response = await axios.post('http://llm-sidecar.local/api/generate', {
prompt: `Crie um roteiro de viagem para ${destino} para um viajante com perfil ${perfil}.`,
});
return {
statusCode: 200,
body: JSON.stringify({
roteiro: response.data.roteiro,
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: 'Erro ao gerar roteiro.' }),
};
}
};
🧠 Back-end do Sidecar (LLM) – Exemplo simples com FastAPI (Python)
from fastapi import FastAPI, Request
from pydantic import BaseModel
import openai # ou outro modelo hospedado localmente
app = FastAPI()
class PromptRequest(BaseModel):
prompt: str
@app.post("/api/generate")
async def generate_text(prompt_req: PromptRequest):
# Aqui pode usar OpenAI, LLaMA, ou modelo local via transformers
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # ou outro
messages=[{"role": "user", "content": prompt_req.prompt}]
)
generated = response['choices'][0]['message']['content']
return {"roteiro": generated}
☁️ Onde o LLM pode estar hospedado?
-
Num container Docker na mesma VPC do seu serverless.
-
Num Kubernetes cluster.
-
Num serviço como Replicate, Hugging Face Inference API ou OpenAI.
const functions = require("firebase-functions");
const axios = require("axios");
exports.gerarRoteiro = functions.https.onRequest(async (req, res) => {
const { destino, perfil } = req.body;
try {
const resposta = await axios.post('https://meu-llm-em-cloud-run.com/api/generate', {
prompt: `Crie um roteiro de viagem para ${destino} para um perfil de viajante ${perfil}.`
});
res.status(200).send({ roteiro: resposta.data.roteiro });
} catch (erro) {
console.error("Erro ao chamar LLM:", erro);
res.status(500).send({ erro: "Falha ao gerar roteiro." });
}
});
🧠 Lado do LLM (rodando como sidecar)
Você pode:
-
Criar uma API com FastAPI (Python).
-
Botar isso num container Docker.
-
Hospedar em Google Cloud Run (super fácil e integrado com Firebase).
Se quiser, te ajudo a montar esse Dockerfile e deploy no Cloud Run também!
☁️ Alternativas se não quiser rodar modelo local:
-
OpenAI API: Substitui o
https://meu-llm...porhttps://api.openai.com/v1/chat/completions -
Hugging Face: Usa os modelos deles direto, só precisa token.
Ta na dúvida entre montar a API do LLM Ou usar OpenAI direto ?
Boa, dúvida é bom — sinal que tu tá pensando estrategicamente 😎
Vamos facilitar tua decisão. Aqui vai uma comparação direta entre rodar teu próprio LLM (sidecar) e usar um LLM pronto como o da OpenAI:
🔧 RODAR SEU PRÓPRIO LLM (sidecar)
✔️ Vantagens:
-
✅ Controle total sobre o modelo (pode afinar, personalizar, rodar localmente)
-
✅ Sem custo por requisição (paga só o hosting)
-
✅ Sem depender de terceiros (tipo OpenAI caindo)
❌ Desvantagens:
-
⚠️ Precisa cuidar de infraestrutura (hospedagem, segurança, etc.)
-
⚠️ Modelos grandes exigem GPU (custa caro)
-
⚠️ Latência pode ser maior se o serviço não estiver otimizado
Bom pra: quando você quer autonomia, customização ou reduzir custos a longo prazo.
🌐 USAR OPENAI OU HUGGING FACE API
✔️ Vantagens:
-
✅ Fácil de usar (só chamar a API com um
POST) -
✅ Alta qualidade dos modelos (tipo GPT-4, LLaMA 2, etc.)
-
✅ Sem se preocupar com infraestrutura ou atualização
❌ Desvantagens:
-
⚠️ Custo por uso (cada requisição custa)
-
⚠️ Dependência de terceiros
-
⚠️ Dados sensíveis precisam ser tratados com cuidado
Bom pra: começar rápido, fazer MVPs, ou quando você quer o top de linha sem dor de cabeça.
🧠 Resumo estilo “Claudio Programador”:
| Critério | Rodar o seu LLM (Sidecar) | Usar OpenAI/Hugging Face |
|---|---|---|
| 🛠 Infraestrutura | Você cuida | Eles cuidam |
| 💸 Custo inicial | Médio/Alto | Baixo |
| 🔄 Flexibilidade | Alta | Média |
| 🧠 Inteligência | Depende do modelo | Altíssima (GPT-4 etc.) |
| 🕐 Tempo pra subir | Maior | Rápido |